Jupyter 项目工作原理介绍
实习所在的公司做的产品需要与数据打交道,所以最近有实现类似 Jupyter 这种在线交互执行环境。让用户可以和他们自己上传的数据交互。经过调研最终决定在 Jupyer 和 Zeppelin 这两个开源的平台中的一个进行二次开发。所以需要去了解他们的原理,本文介绍 Jupyter 的原理。
Jupyter 项目是什么
Jupyter 是一个开源项目,旨在为交互式计算提供支持,特别是在数据科学、机器学习、科学计算和教育领域。如果没有使用过的话,可以去 Jupyter 官方提供的 在线体验地址 熟悉熟悉。Jupyter 在社区支持、应用规模、用户习惯等方面都比 Zeppelin 会更好。下面我们来了解一下 Jupyter 项目的生态和一些重要组件的原理。
Jupyter 项目生态
Jupyter 项目有多个组件组成,通过不同的组件可以构造出不同的应用。组件之间的依赖关系如下图所示:
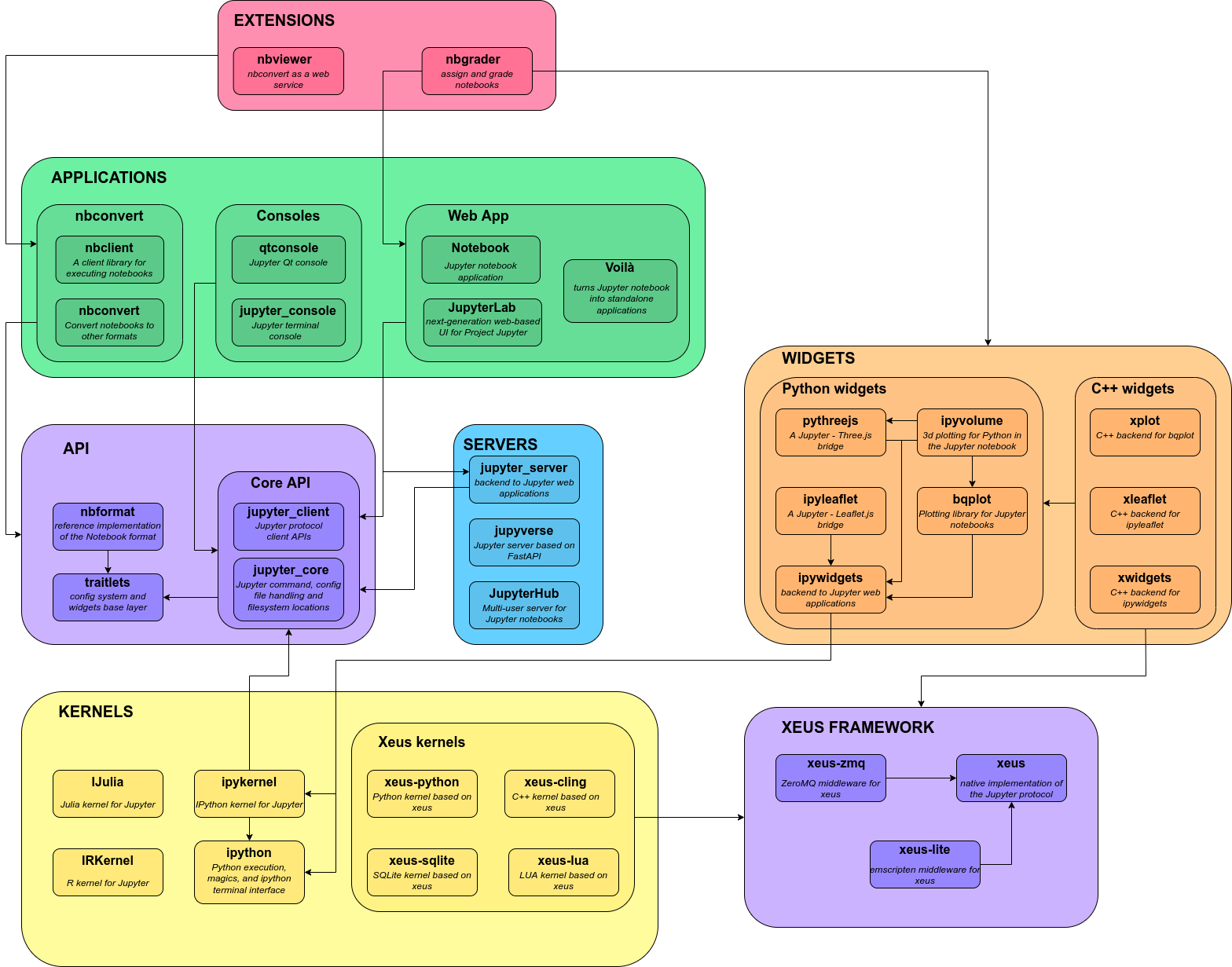
上述架构中的各组件分别是:
- EXTENSIONS : 这个组件是扩展,扩展 Jupyter 的功能,提供额外的工具和服务,增强用户体验。扩展通常作为插件安装,可以与 Jupyter Notebook 、JupyterLab 等前端集成,增强基础功能。用户可以通过命令行或配置文件启用这些扩展。
- APPLICATIONS : 这个组件是用户接口,提供不同形式的 Jupyter 用户界面和工具,满足各种需求。用户通过浏览器或桌面应用程序访问这些应用,使用它们进行编程、数据分析和可视化。不同的应用通过 Jupyter Server 提供的 API 进行交互。
- WIDGETS : 这个组件是小部件,提供交互式组件,增强 Notebook 的互动性。小部件通常在 Notebook 中使用,通过内核执行代码,与用户交互并动态更新显示内容。
- API : 这个组件是 API,提供核心功能的编程接口,支持扩展和定制。开发者可以使用这些 API 扩展 Jupyter 的功能,创建自定义的应用和服务。
- SERVERS : 这个组件是服务器,提供后端服务,管理用户会话和内核,处理客户端请求。服务器管理用户会话和内核,通过 HTTP/HTTPS 、WebSocket 协议与客户端(如 Notebook 或 JupyterLab)通信,处理执行代码和返回结果。
- KERNELS : 这个组件是内核,执行用户代码,返回计算结果。内核通过 Jupyter 协议与客户端通信,接收代码执行请求并返回结果。内核可以支持多种编程语言。
- XEUS FRAMEWORK : 这个组件提供一个实现 Jupyter 协议的框架,支持创建高性能内核。
上述架构中各组件之间的关系是:
- 用户界面(JupyterNotebook、JupyterLab):通过浏览器或应用程序访问,向服务器发送请求。
- 服务器(JupyterHub、jupyter_server):处理用户请求,管理会话和内核,使用 API 与内核通信。
- 内核(ipykernel、IRKernel、xeus-python):执行用户代码,返回结果给服务器。
- 小部件(ipywidgets、bqplot):嵌入在 Notebook 中,与用户交互,通过内核执行代码,动态更新显示内容。
- 扩展(nbviewer、nbgrader):增强用户界面和功能,通过 API 与核心组件交互。
通过这些组件的协同工作,Jupyter 项目提供了一个功能强大且灵活的交互式计算平台,满足了不同用户的多种需求。
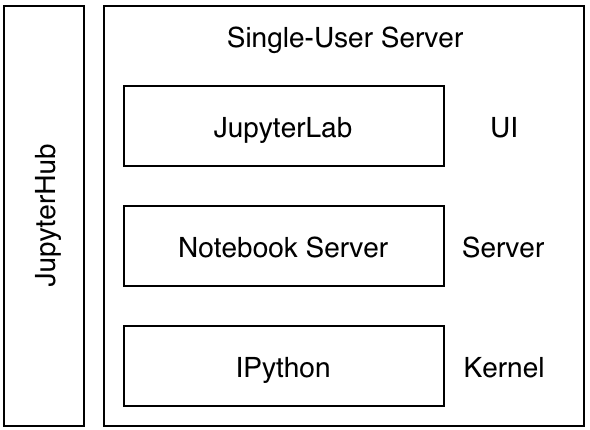
Jupyter 平台其实就是一个 Web 服务,我们可以从这个维度来看 Jupyter 的架构。前面的描述看起来很复杂,但是简化一下就是下面这幅图。
Jupyter 平台通过 JupyterHub 管理多个用户,每个用户都有独立的单用户服务器实例,包括 Jupyter Lab 界面、Jupyter Server 和 IPython 内核。用户通过 JupyterLab 交互界面编写和执行代码,Notebook Server 处理请求并与内核通信执行代码,最终将结果返回给用户,实现了多用户的交互式计算环境。
下面介绍各个组件中比较常用的应用。
用户接口组件
用户接口的任务很简单,提供界面给用户使用,用户在界面进行的操作会发送到服务端进行请求。下面是两个常用的界面 Jupyter Notebook 和 Jupyter Lab。
Jupyter Notebook
Jupyter Notebook 是最经典的界面它的特点主要有以下几点:
单一文档界面:用户界面主要是一个单一的 Notebook 文档,可以包含代码、文本、图表和其他富媒体内容。
简洁直观:设计简洁,容易上手,适合于基本的数据分析、教学和研究。
扩展支持:支持通过扩展来增加功能,但扩展性较有限。
专注于 Notebooks:主要功能集中在编辑和执行 Jupyter Notebooks。
它使用的场景主要简单的单文档工作流,如教学、学习和基本数据分析。
Jupyter Lab
Jupyter Lab 的特点主要有以下几点:
- 多文档界面:支持多标签和多窗口,可以在同一个界面中同时打开和操作多个 Notebooks、终端、文本文件、图表等。
- 高度可定制:提供更多的定制选项和插件系统,用户可以通过拖放组件来定制工作环境。
- 集成开发环境:集成了终端、文件浏览器、代码控制等工具,类似于一个全功能的 IDE(集成开发环境)。
- 增强的扩展性:有更强的扩展能力,支持更多的第三方插件,能够实现更多复杂的工作流。
它使用的场景主要是更复杂的工作流和专业的数据科学和开发任务。
服务端组件
服务端的任务是接受前端发来的请求,与内核进行交互,将执行结果返回给前端。下面介绍 Jupyter Server 的原理。
Jupyter Server
Jupyter Server 提供了后端服务(例如:核心服务、REST API)给前端界面(Jupyter notebook、JupyterLab)使用。
架构
在 Jupyter Server 的文档中介绍了它的 架构,如下图所示:
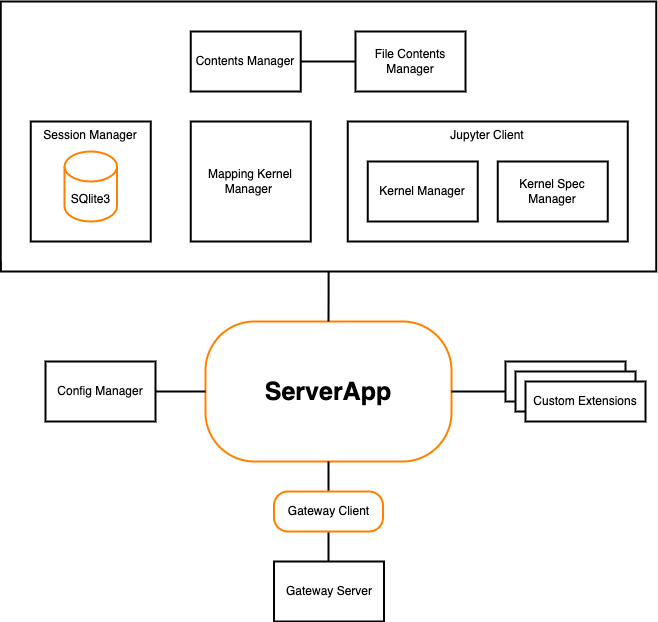
Jupyter Server 包括以下组件:
ServerApp 是基于 Tornado (python web 应用框架)的主要应用程序,它将所有组件连接在一起。
**Config Manager **初始化 ServerApp 的配置。可以使用此配置为 Jupyter Server 管理器定义自定义类并更改 ServerApp 设置。按照配置文件指南 了解配置设置以及如何构建自定义配置。
Custom Extensions 允许创建自定义服务器的 REST API 端点。需要遵循 扩展指南 以了解有关使用额外请求处理程序扩展 ServerApp 的更多信息。
Gateway Server 是一个 Web 服务器,配置后,它可以访问在其他主机上运行的 Jupyter 内核。创建网关服务器的方法有很多种。如果 ServerApp 需要与位于资源管理集群中的远程内核通信,则可以使用 Enterprise Gateway,否则,可以使用 Kernel Gateway,其中内核在 Gateway Server 本地运行。
Contents Manager 和 File Contents Manager 负责在文件系统上为 前端 Notebook 提供服务。Session Manager 使用 Contents Manager 接收内核路径。可以参考 Contents API 指南 来了解 Contents Manager。
Session Manager 处理用户的会话(即与内核的交互)。当用户启动新内核时,会话管理器将启动一个进程来为用户配置内核并生成新的会话 ID。每个打开的 Notebook 都有一个单独的会话,但不同的 Notebook 内核可以使用相同的会话,这样可以在不同的 Notebooks 之间共享数据。例如,用户可以在一个 Notebook 中定义变量或函数,然后在另一个 Notebook 中使用它们。Session Manager 使用 SQLite3 数据库来存储会话信息。数据库默认存储在内存中,但可以配置为保存到磁盘。
Mapping Kernel Manager 负责管理在 ServerApp 中运行的内核的生命周期。它为用户会话启动一个新内核,并协助针对内核执行中断、重启和关闭操作。
Jupyter Server 使用Jupyter Client库与 Notebook 内核协同工作。
- Kernel Manager 管理 Notebook 的一个内核。要了解有关内核管理器的更多信息,可以参考 Jupyter 客户端 API 文档。
- Kernel Spec Manager 解析具有内核 JSON 规范的文件,并提供可用内核配置列表。要了解 Kernel Spec Manager,可以参考 Jupyter Client 指南。
创建会话工作流程
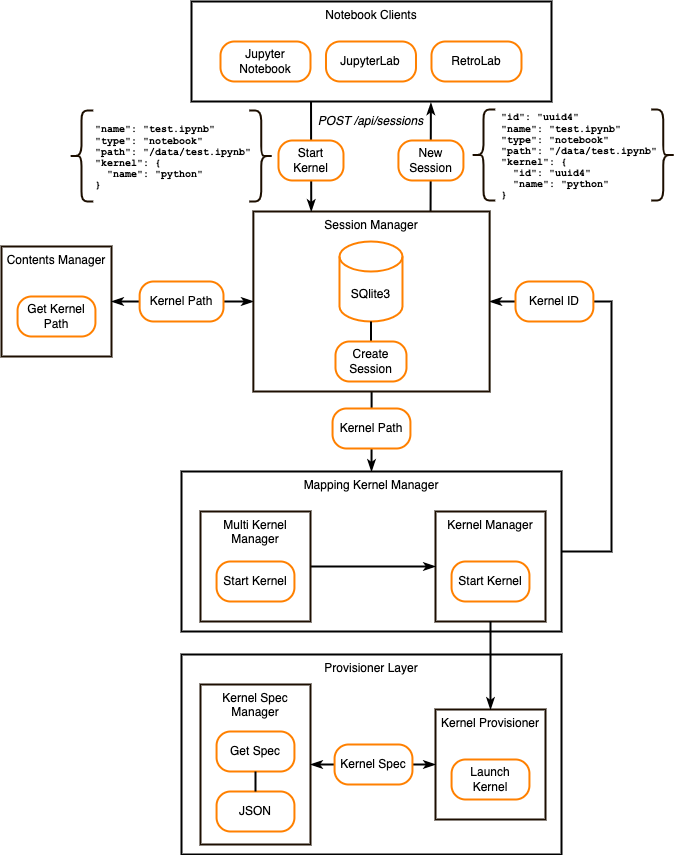
如上图所示,当用户启动新内核时,会发生以下步骤:
- Notebook 客户端向 Jupyter Server 发送 POST /api/sessions 请求。此请求包含所有必要的数据,例如 Notebook 名称、类型、路径和内核名称。
- Session Manager 根据输入数据向 Content Manager 请求内核在文件系统中的路径。
- Session Manager 将内核路径发送给 Mapping Kernel Manager。
- Mapping Kernel Manager 使用 Mutil Kernel Manager 和 Kernel Manager 启动内核创建过程。
- Kernel Manager 通过 provisioner layer 来启动一个新内核。
- Kernel Provisioner 负责根据内核规范启动内核。如果内核规范未定义 provisioner,则使用 Local Provisioner 启动内核。开发者可以通过 Kernel Provisioner Base 和 Kernel Provisioner Factory 创建自定义配置器。
- Kernel Spec Manager 从 JSON 文件中获取内核规范。该规范位于
kernel.json文件中。 - 一旦 Kernel Provisioner 启动内核, Kernel Manager 就会为 Session Manager 生成新的内核 ID 。
- Session Manager 将新的会话数据保存到 SQLite3 数据库(会话 ID, Notebook 路径, Notebook 名字, Notebook 类型, 内核ID)。
- Notebook 客户端接收 创建的 Session 数据。
删除会话工作流程
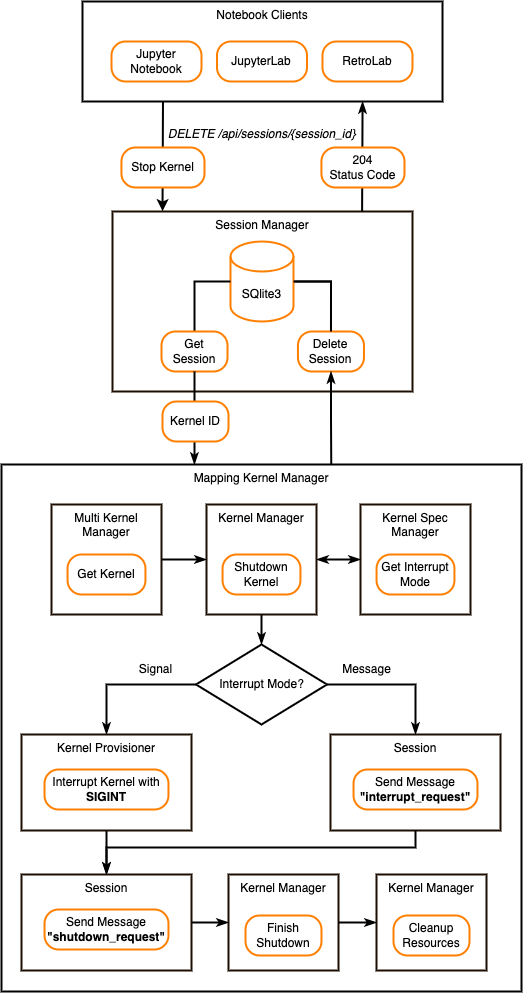
如上图所示,当用户停止内核时,会发生以下步骤:
- Notebook 客户端向 Jupyter Server 发送 DELETE /api/sessions/{session_id} 请求。此请求具有内核当前正在使用的会话 ID。
- Session Manager 从 SQLite3 数据库获取会话数据,并将内核 ID 发送给 Mapping Kernel Manager。
- Mapping Kernel Manager 使用 Mutil Kernel Manager 和 Kernel Manager 启动内核关闭过程。
- Kernel Manager 从 Kernel Spec Manager 中确定中断模式。它支持
Signal和Message中断模式。默认情况下,Signal使用中断模式。- 当中断模式为时
Signal,Kernel Provisioner 会使用操作系统信号中断内核SIGINT(尽管其他 Provisioner 实现可能使用不同的方法)。 - 当中断模式为时
Message,Session 在控制通道上发送 “interrupt_request”消息。
- 当中断模式为时
- 中断内核后,Session 在控制通道上发送 “shutdown_request”消息。
- Kernel Manager 等待内核关闭。超时之后,如果 Kernel Manager 检测到内核进程仍在运行,则它会发送
SIGTERM操作系统信号(或等效的配置程序)来终止内核。如果 Kernel Manager 发现内核进程没有终止,它将发送一个SIGKILL操作系统信号(或等效的提供程序),以确保内核的终止。 - Kernel Manager 清理内核资源。它删除内核的进程间通信端口,关闭控制套接字,并释放 Shell、IOPub、StdIn、Control 和 Heartbeat 端口。
- 当关闭完成后,Session Manager会从 SQLite3 数据库中删除会话数据,并向 Notebook 客户端响应 204 状态代码。
内核组件
Jupyter 的内核组件(Kernel)是执行用户代码并返回结果的核心组件。每个内核实例对应一种编程语言,并且负责处理来自 Jupyter Notebook 或 JupyterLab 的执行请求。这些请求经过 Jupyter Server 转发给 Kernel。下面介绍常用的 IPython Kernel。
IPython
解耦双进程模型
IPython 是基于“解耦双进程模型”实现的。
REPL(Read-Evaluate-Print Loop)是传统的交互式编程环境,包括读取用户输入、评估表达式、打印结果和循环操作。IPython 将评估(evaluate)过程抽象并分离到一个独立的进程中,这个进程被称为内核(kernel)。客户端(client)负责向内核发送执行指令,并接收内核返回的结果。
它的实现方式是基于客户端和内核实现的。内核是一个独立的进程,负责实际的代码执行。内核接收来自客户端的执行指令,执行代码,并将结果返回给客户端。客户端是用户与内核交互的接口,负责发送执行指令并显示结果。客户端和内核可以运行在同一台机器上,也可以分布在不同的机器上。
这种方式的优点是:1. 多个客户端可以连接到同一个内核,这使得不同的用户或应用可以共享同一个执行环境。2. 客户端和内核可以在不同的机器上运行,这种分布式架构支持更复杂的计算和资源管理。
一个应用实例是:当启动 Jupyter QtConsole 时,实际上启动了两个进程:一个内核进程和一个基于 Qt 的客户端。客户端向内核发送命令,并接收和显示内核返回的结果。使用 –existing 参数可以连接到已存在的内核,而不需要启动新的内核。例如:jupyter qtconsole --existing。使用 %connect_info 魔法命令可以获取连接文件信息,例如 --existing kernel-19732.json,其中包含内核的进程 ID。
客户端和内核的需要遵守特定的消息协议。这个消息协议定义了内核和客户端之间的消息格式和传递方式,确保指令和结果能够正确传递。
IPython 通过解耦的两进程模型将代码执行和用户交互分离,实现了更灵活和强大的交互式编程环境。这个模型允许多个客户端连接到同一个内核,并支持客户端和内核在不同机器上运行,从而实现了更强的扩展性和分布式计算能力。Jupyter 项目继承了这一模型,扩展了其应用范围,支持多种前端和内核交互方式。也就是说 Jupyter 使用的 IPython 内核指的是 IPython 项目中的一部分。IPython 项目本身还包含 Terminal IPython Shell 等部分。
IPython Kernel
用户前端界面(Notebook、Qt console、Terminal IPython 和第三方界面)都使用 IPython Kernel。这是一个单独的进程,负责运行用户代码等。前端使用通过 ZeroMQ 套接字发送的 JSON 消息与 IPython Kernel 通信;它们使用的协议 在 Jupyter 中的消息传递 中进行了描述。
IPython Kernel 的 Python execution 核心执行机制与 Terminal IPython 共享,如下图所示:

一个内核进程可以同时连接到多个前端。在这种情况下,不同的前端将可以访问相同的变量。
这种设计的目的是为了能够基于相同内核轻松开发不同的前端,但它也使得在相同的前端中支持新语言成为可能,通过在这些语言中开发内核,开发社区正在改进 IPython 以使其更加实用。
目前,有两种方法可以为另一种语言开发内核。Wrapper Kernel 重用 IPython 中的通信机制,并仅实现核心执行部分。Native Kernel 实现目标语言的核心执行部分和通信通信部分。如下图所示:

对于有很好的 Python 包装器的语言(如 octave_kernel )或者对于实现通信机制不切实际的语言(如 bash_kernel ) ,Wrapper Kernel 更容易快速编写。Native Kernel 可能会由使用它们的社区更好地维护,如 IJulia 或 IHaskell。
如果想要自己实现一种语言的内核,可以参考 IPython 官方编写 Wrapper Kernel 的简单示例。
IPython Kernel 的执行过程
当 IPython Kernel 接收到带有用户代码的 execute_request 时 ,它会按照以下阶段处理该消息:
- 在执行代码前触发
pre_execute事件。 - 在运行代码单元前触发
pre_run_cell(如果silent参数为True,则不会触发)。 - 执行
run_cell方法进行预处理、编译并运行用户代码。 - 如果代码执行成功,内核会计算
user_expressions中的表达式。这些表达式的计算是在主要代码执行后进行的,因此它们的错误不会影响主要代码的执行。 - 触发
post_execute事件。 - 在运行代码单元后触发
post_run_cell(如果silent参数为True,则不会触发)。例如,Notebook 前端会利用此事件来显示图形。
IPython 内核在执行代码的过程中,会触发一系列事件。开发者可以定义这些事件的内容,以便在代码执行的不同阶段执行自定义逻辑。每个事件都可以注册回调函数(Callbacks),这些回调函数会在相应事件触发时被调用。不同事件的详细作用可以参考 IPython 事件。
run_cell 方法会执行用户代码,具体过程如下所示:
- 预处理
- 首先,代码 cell 被 IPython.core.inputtransformer2 转换为
%magic和!system扩展命令。这些命令是 IPython 特有的,允许用户在代码中执行系统命令或特定的 IPython 命令。
- 首先,代码 cell 被 IPython.core.inputtransformer2 转换为
- 编译
- 扩展后的代码使用 Python 的
compile()函数进行编译。compile()函数的mode参数决定了代码的编译方式。 - 当 mode 为 single :用于单一交互式语句。如果代码块中包含多个表达式,每个表达式返回一个值时会多次调用
sys.displayhook() - 当 mode 为 exec :用于执行任意数量的代码块,例如模块的编译。在这种模式下,
sys.displayhook()不会被自动调用。 - 当 mode 为 eval :用于执行单个表达式并返回一个值。在这种模式下,
sys.displayhook()也不会被自动调用。
- 扩展后的代码使用 Python 的
- 执行
- 代码会被分割为多个块,每个块在适当的模式下执行。
- 如果只有一个代码块,则在
single模式下执行。 - 如果有多个代码块,且最后一个代码块是一行或两行,前面的代码块会在
exec模式下执行,最后一个代码块在single模式下执行。 - 如果最后一个代码块是多行代码,则所有代码块在
exec模式下作为一个单元执行。
部署组件
Kernel Gateway
简介
Jupyter Kernel Gateway 是一个为 Jupyter 内核提供无头访问(headless access)的 Web 服务器,允许应用程序通过 REST API 和 WebSocket 与 Jupyter 内核进行远程通信。
什么是无头访问?Jupyter Kernel Gateway 允许应用程序在没有 Jupyter Notebook 用户界面的情况下访问和使用 Jupyter 内核。这意味着你可以在没有传统 Jupyter Notebook 前端的情况下,远程控制和使用内核。
通信方式是什么?应用程序可以通过 REST API 与内核进行通信,例如启动和停止内核、发送代码执行请求等。通过 WebSocket,应用程序可以使用 Jupyter 内核协议发送代码片段并接收执行结果,而不依赖于 ZeroMQ(Jupyter 内核通常使用的消息传递协议)。
Kernel Gateway 只提供对内核的访问和控制,不提供编辑 Jupyter Notebooks 的功能。因此,它主要用于代码执行和内核管理,而不是用于创建或编辑 Notebook 文档。
支持的操作模式主要有下面两种:
- 代码片段执行模式:在这种模式下,应用程序可以通过 WebSocket 使用 Jupyter 内核协议发送代码片段进行执行。内核的启动和停止可以通过 REST API 控制。这种操作方式与 Jupyter Notebook Server 的相应 API 部分兼容,因此可以无缝集成到已有的工作流程中。
- HTTP 请求模式:Kernel Gateway 可以根据带有注释的 Notebook 单元格来处理 HTTP 请求。注释定义了支持的 HTTP 动词(如 GET、POST)和资源。当收到 HTTP 请求时,Kernel Gateway 会执行配置好的 Notebook 中的某个单元格,以响应请求。这使得你可以将 Notebook 配置为处理 HTTP 请求的后端,形成一种轻量级的微服务架构。
Kernel Gateway 使用与 Jupyter Notebook 相同的代码来启动内核,并在本地进程/文件系统空间中管理这些内核。这意味着它与 Jupyter Notebook 的内核管理逻辑保持一致。Kernel Gateway 可以被容器化(例如使用 Docker),并通过 tmpnb、Cloud Foundry、Kubernetes 等技术进行扩展。这使得它能够在云环境中大规模部署,并在大数据环境中与计算集群(如 Spark)集成。
以下是相关的使用场景:
- 与云计算集群的交互:Kernel Gateway 可以连接本地 Jupyter Notebook 服务器到云中的计算集群,靠近大数据源进行交互(例如,作为与 Spark 交互的网关)。
- 为非 Notebook 的 Web 客户端提供内核支持:开发新型的 Web 客户端,这些客户端无需 Notebook 界面即可创建和使用内核(例如,通过 jupyter-js-services 实现的 Web 仪表盘)。
- 从 Notebook 创建微服务:使用 Kernel Gateway 的 HTTP 模式,可以将 Notebook 中的代码转换为微服务,通过 HTTP 请求触发执行,形成一种轻量级的服务架构。
Jupyter Kernel Gateway 是一个灵活的工具,用于通过 Web 接口远程控制和使用 Jupyter 内核。它可以在没有 Notebook 界面的情况下执行代码,并且支持多种通信方式和操作模式。Kernel Gateway 非常适合需要在分布式云环境中大规模使用内核、创建基于 Notebook 的微服务或为非 Notebook 的 Web 客户端提供内核支持的场景。
使用
下面列举一些命令,具体可以参考 官方教程:
1 | # 从 pypi 安装 |
案例
Jupyter Kernel Gateway 使 Jupyter Kernel 有了如下新的用途:
- 将本地 Jupyter Notebook 服务器连接到在云端运行大数据的计算集群(例如,Spark 的交互式网关)
- 使新型非 Notebook Web 客户端能够配置和使用内核(例如,使用 jupyter-js-services 的仪表板)
- 独立于客户端扩展内核(例如,通过 tmpnb、Binder 或其他集群管理器)
- 通过 http-mode 从笔记本创建微服务
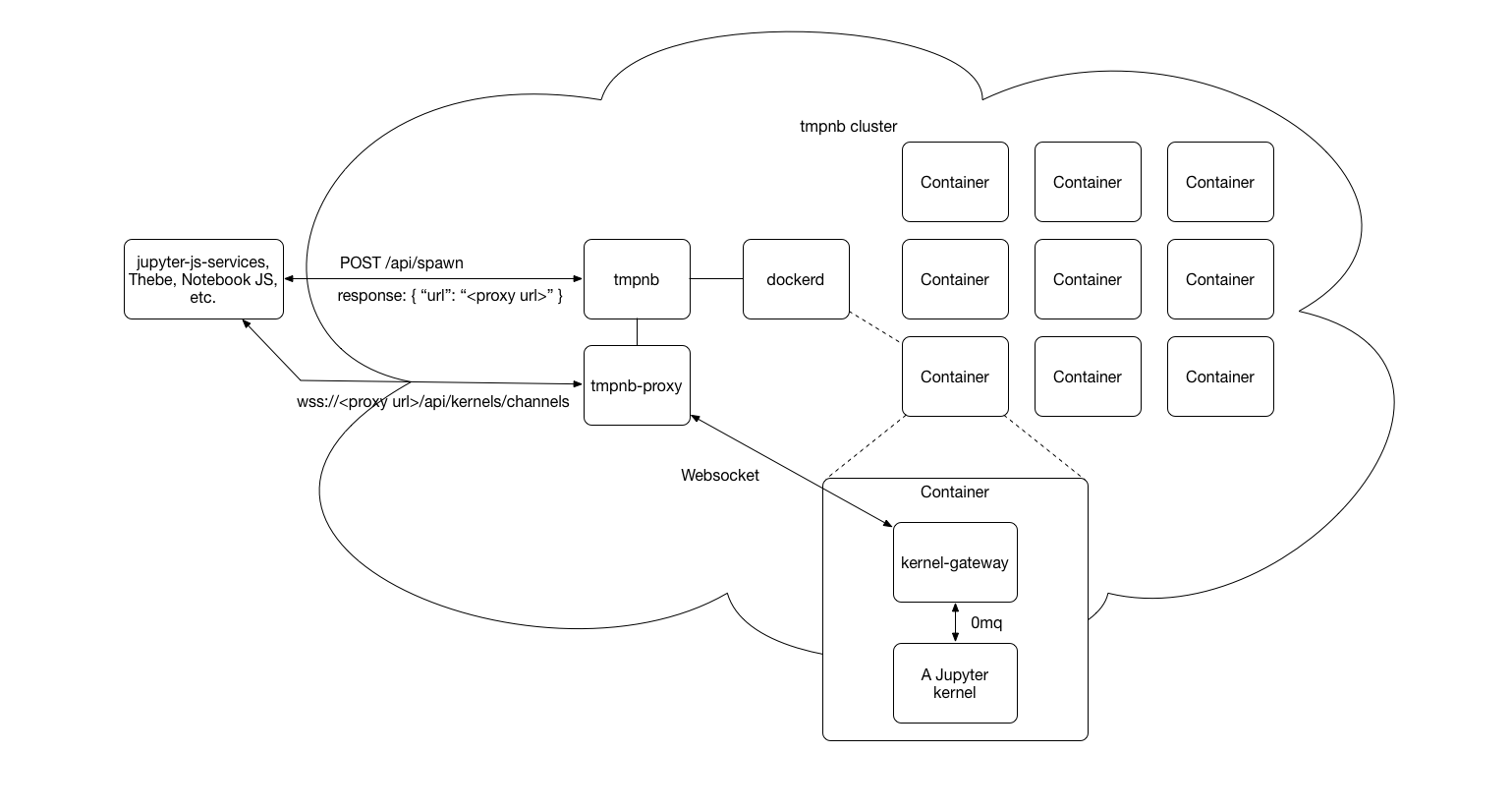
上图展示了如何使用 tmpnb 在 Docker 容器中部署内核网关实例池,以支持按需交互式计算。其中客户端(如 jupyter-js-services 或 Thebe)通过 HTTP 请求向 tmpnb 发送内核启动请求,tmpnb 调用 Docker 启动容器并运行 Jupyter Kernel Gateway。随后,tmpnb-proxy 将客户端的 WebSocket 请求路由到对应的容器中的内核实例,实现按需的交互式计算,返回结果给客户端。这种架构支持动态扩展和高效管理多个独立的内核实例。
官方 jupyter/kernel_gateway_demos 提供了更多的 demo 供开发者参考。
Enterprise Gateway
简介
Jupyter Enterprise Gateway 使 Jupyter Notebook 能够在分布式集群中启动远程内核,包括由 YARN、IBM Spectrum Conductor、Kubernetes 或 Docker Swarm 管理的 Apache Spark。这意味着你可以在大型计算集群上运行 Jupyter 内核,从而在这些集群上执行代码,而不仅仅是在本地计算机上。
它为以下内核提供开箱即用的支持:
- 使用 IPython 内核的 Python
- 使用 IRkernel 的 R
- 使用 Apache Toree 内核的 Scala
Jupyter Enterprise Gateway 不管理多个 Jupyter Notebook 部署,如果你需要管理多个 Jupyter Notebook 实例,例如为多个用户提供独立的 Notebook 服务器,那么应该使用 JupyterHub。
Jupyter Enterprise Gateway 其实是一个 Web 服务器,可在企业内提供对 Jupyter 内核的无头访问。Jupyter Enterprise Gateway 受到 Jupyter Kernel Gateway 的启发,除了提供以下功能外,还提供与 Kernel Gateway 的 jupyter-websocket 模式 相同的功能:
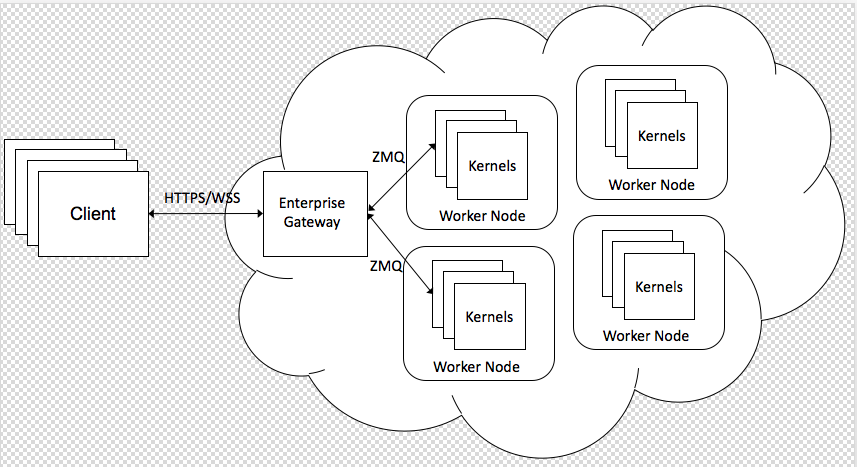
- 远程内核支持:Jupyter Enterprise Gateway 允许在分布式集群的不同节点上启动和管理 Jupyter 内核。图片中的 Worker Nodes 就是这些分布式节点,内核可以根据需要在这些节点上动态启动。内核的启动方式可以是本地的,也可以是通过分布式资源管理器(如 YARN、Kubernetes)来分配的。
- 多种启动方式:Enterprise Gateway 可以通过轮询算法将内核分配到不同的节点,确保负载均衡。Enterprise Gateway 也可以根据资源管理器的指示,在特定的节点上启动内核。
- 安全通信:客户端通过 HTTPS 或 WSS 与 Enterprise Gateway 进行安全通信。然后,Enterprise Gateway 再通过 ZMQ 与远程内核通信,这确保了整个通信链路的安全性。
- 多租户支持:Enterprise Gateway 支持多租户能力,允许多个用户在同一环境中使用各自的内核实例,而不会相互干扰。图片中多个客户端连接到同一个 Gateway,但执行的内核是独立的。
- 持久的内核会话:Enterprise Gateway 支持持久的内核会话,意味着即使客户端暂时断开连接,内核仍然保持活跃状态,等客户端重新连接时可以继续使用之前的会话。
- 配置文件关联:Enterprise Gateway 可以根据用户或特定任务的需求,将配置文件与内核实例关联。这些配置文件可以包括内存限制、CPU 配额等资源配置,确保每个用户或任务都能获得适当的资源。
使用
1 | # install from pypi |
请参考 官方使用教程
如果需其他资源管理器编写应用程序或部署内核,参考官方的 开发人员指南。
Kernel Gateway 和 Enterprise Gateway 的区别
Kernel Gateway 和 Enterprise Gateway 最大的区别是:Kernel Gateway 路由 Kernel Gateway 部署所在路由器上的内核,Enterprise Gateway 路由 一个集群里面的内核。
Kernel Gateway 适用于以下场景:
- 有一个小型用户池,其中网关服务器的资源可以在这些用户之间共享(不支持远程内核)
- 希望配置 http mode 功能,其中特定 Notebook 提供 HTTP 端点
Enterprise Gateway 适用于以下场景:
- 有一个由有限资源(GPU、大内存等)组成的大型计算集群,并且用户需要从笔记本电脑中获取这些资源
- 有大量用户需要访问共享计算群集
- 需要一定程度的高可用性/灾难恢复,以便可以启动另一个网关服务器来为现有(和远程)内核提供服务
Jupyter Hub
简介
JupyterHub 是为多用户提供 Jupyter Notebook 的最佳方式。由于 JupyterHub 为每个用户管理单独的 Jupyter 环境,因此它可以用于一班学生、一个企业数据科学小组或一个科研小组。它是一个多用户 Hub,可以生成、管理和代理单用户 Jupyter Notebook 服务器的多个实例。
JupyterHub 既可供小型团队(0-100 名用户)使用,也可供大型团队(超过 100 名用户)在协作环境中使用,例如一班学生、企业数据科学小组或科学研究小组。它有两个主要发行版,分别针对每个团队的需求而开发。
- Littlest JupyterHub 发行版适合少量用户(1-100)和具有简单环境的单个服务器 的场景。
- 在 k8s 上从 0 部署 jupyterhub 允许您在云上部署动态服务器,适合更多用户 的场景。
组成
JupyterHub 由四个子系统组成:
- Hub(tornado 进程)是 JupyterHub 的核心。
- configurable http proxy ( node-http-proxy),用于接收来自客户端浏览器的请求
- 由 Spawners 监控的多个 single-user Jupyter notebook servers (Python/IPython/tornado)
- 管理用户如何访问系统的 authentication class
此外,可以通过文件添加可选配置 config.py,并在管理面板上管理用户的内核。下图显示了整个系统的简化图:
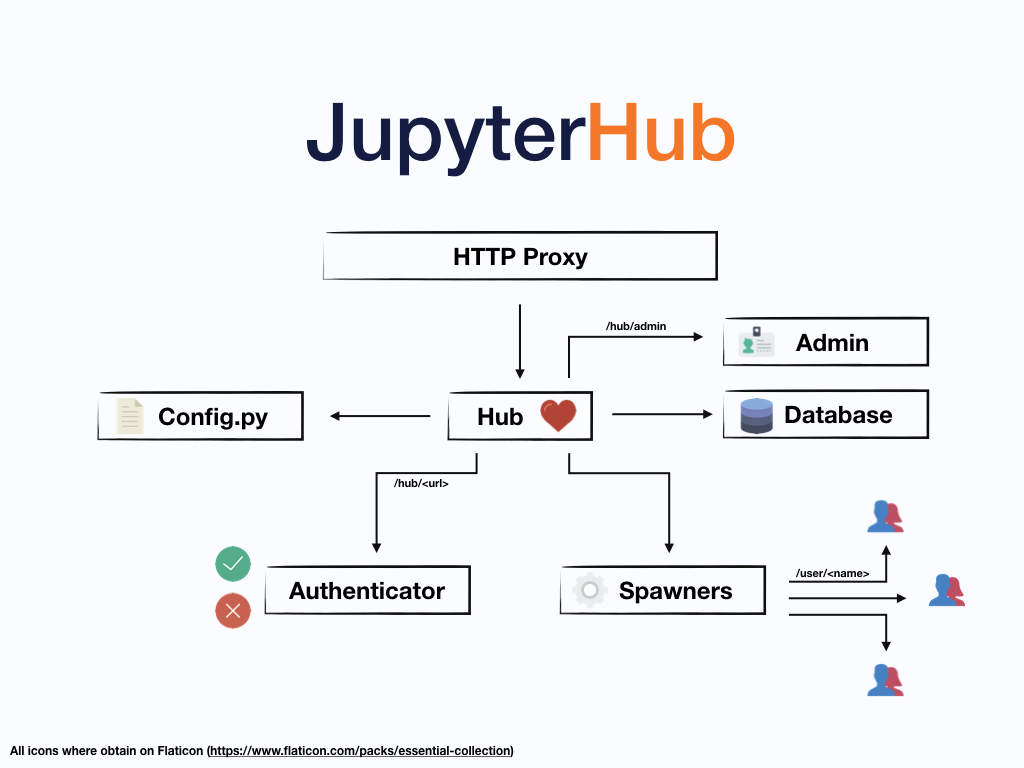
JupyterHub 执行以下功能:
- Hub 启动代理
- 代理默认将所有请求转发到 Hub
- Hub 处理用户登录并根据需要生成单用户服务器
- Hub 配置代理以将 URL 前缀转发到单用户笔记本服务器
为了方便管理 Hub、其用户和服务,JupyterHub 还提供了REST API。
使用
如何安装使用,就不赘述了,官方使用教程 写的很全。
如果需要二次开发的话,可以参考 官方技术文档。
总结
Jupyer 项目的社区和生态都是比较成熟的,很适合用来做 数据平台 Notebook 的二次开发。本文介绍了 Jupyter 项目中的各个组件的作用,并简述了原理。通过使用不同的组件可以组合出不同的应用。了解了这些,可以根据自己的工作场景,选择适合的组件进行部署和二次开发。