Notebook 商业化服务调研
本文对目前 Notebook 的商业化服务进行调研分析,包括它们的架构原理,最后总结与图数据库和 Spark 相关的 Notebook 特点与原理。
1. 概述
Notebook 商业化服务 是指由企业或平台提供的基于 Jupyter Notebook 或类似交互式计算环境的在线服务,这些服务通常提供了更强大的计算资源、数据管理、协作工具和技术支持,适合个人用户、企业和研究机构使用。这些服务通常是付费的,或者在基础功能之上提供付费的高级功能和支持,这是“商业化”的方式。通过提供强大的计算资源、灵活的环境配置和全面的技术支持,帮助用户更高效地进行数据分析、机器学习、科学计算等任务。
2. 对比分析
下面对目前的主流商业化 Notebook 商业化服务进行分析,从基本功能、使用场景、后台使用的计算资源、与自家生态结合程度、用户界面、扩展性和商业化方式进行总结与梳理。
以下是总结后的表格,方便对比分析:
| 产品名称 | 基本功能 | 使用场景 | 后台使用的计算资源 | 与自家生态结合程度 | 用户界面 | 扩展性 | 商业化方式 |
|---|---|---|---|---|---|---|---|
| Google Colab | 免费在线 Jupyter Notebook,内置代码库、可视化插件、Markdown 支持 | 数据科学、机器学习初学者及轻量级项目 | Google Cloud 资源,支持 GPU 和 TPU | 与 Google 产品如 Drive、Cloud 等深度集成 | 简单易用,类似 Jupyter Notebook | 支持连接本地 Jupyter 和 Google Cloud | 免费使用,高级版本收费 |
| AWS SageMaker | 集成 Jupyter Lab、RStudio 的机器学习开发平台 | 企业级机器学习模型训练、部署和管理 | AWS 云计算资源,支持大规模分布式训练 | 与 AWS 服务如 S3、Lambda、CloudWatch 深度集成 | 托管 Jupyter 笔记本界面,功能强大 | 支持 MLOps 工作流自动化,集成 AWS 服务 | 按计算资源和存储收费 |
| Databricks Notebook | 基于 Apache Spark 的多语言 Notebook 环境 | 大数据处理、数据工程、机器学习 | 云端 Spark 集群,支持大规模并行计算 | 与 Apache Spark 原生集成,Azure 版本与 Azure 服务集成 | 多语言支持,提供协作和版本控制功能 | 高度可扩展,支持与云服务、BI 工具集成 | 按计算资源收费,提供企业级支持 |
| 火山引擎 | 在线 Jupyter Notebook,支持 Python 和 Spark 内核 | 数据分析、机器学习、大数据处理 | Spark 集群进行计算 | 与火山引擎的其他服务集成 | 基于 Jupyter Notebook 界面,简单易用 | 支持 Python 和 Spark 内核 | 按时长收费 |
| Azure ML Notebooks | Azure 机器学习平台上的全托管 Jupyter Notebook | 企业级机器学习开发与部署 | Azure 云资源,支持大规模分布式训练 | 与 Azure 生态系统如 DevOps、数据存储等深度集成 | 基于 Jupyter Notebook 界面,集成 Azure ML 特性 | 支持 Azure 广泛服务集成,扩展性强 | 按计算资源和服务收费 |
| Kaggle Notebook | 完全托管的 Jupyter Notebook 环境,预装常用库 | 数据科学家、分析师、机器学习工程师,竞赛、探索、学习 | 提供免费的 CPU、GPU 和 TPU 资源 | 与 Kaggle 平台深度集成,支持访问 Kaggle 数据集 | 基于 Jupyter Notebook,简单易用 | 支持与 Kaggle 竞赛和数据集集成,扩展性有限 | 免费提供,适合初学者和竞赛参与者 |
| IBM Watson Studio | 基于云的 Jupyter Notebook 环境,支持多种编程语言和 AI 开发 | 企业级数据科学、机器学习和人工智能开发与部署 | 云端计算资源,支持大规模数据处理和模型训练 | 与 IBM 的数据和 AI 服务深度集成 | 基于 Jupyter Notebook 界面,功能丰富,易于使用 | 支持 IBM 云服务集成,扩展性强 | 按计算资源和服务收费 |
| Paperspace Gradient | 云端 Jupyter Notebook,专为机器学习和深度学习设计 | 深度学习和机器学习模型开发,需强大计算资源 | GPU 和 TPU 资源,支持大规模计算任务 | 与 Paperspace 的 Gradient 平台集成,支持全流程自动化 | 基于 Jupyter Notebook,功能丰富,易于使用 | 支持与 Gradient 平台集成,扩展性较强 | 按计算资源收费,适合企业用户 |
| Google AI Notebooks | Google Cloud 的托管 Jupyter Lab 服务,专为数据科学和机器学习设计 | 使用 Google Cloud 资源进行数据科学和机器学习 | Google Cloud 资源,支持 GPU 和 TPU 加速 | 与 Google Cloud 服务如 BigQuery、Cloud Storage 集成 | 基于 Jupyter Lab,界面现代化,功能全面 | 支持与 Google Cloud 服务广泛集成,扩展性强 | 按计算资源和服务收费 |
| Domino Data Lab | 企业级数据科学平台,支持 Jupyter Notebook、RStudio、Zeppelin | 企业级数据科学、数据工程和机器学习任务 | 支持配置和管理计算资源,如 CPU、GPU,按需扩展 | 支持与企业内部系统和工具集成,适合复杂企业级工作流 | 多工具支持,界面专业,适合企业用户 | 高度可扩展,支持多种编程语言和工具,适合复杂企业应用 | 按计算资源和服务收费,提供企业级功能和支持 |
| CoCalc | 在线协作平台,支持 Jupyter、Julia、LaTeX 等多种工具,适合教育和研究 | 科学计算、数据科学、教育和研究,支持团队协作 | 用户选择计算资源,按时长收费,适合不同规模的计算需求 | 独立平台,支持多种工具协同使用 | 多工具支持,界面灵活,适合教育和研究使用 | 支持多种编程语言和工具,扩展性强 | 按计算资源和使用时长收费,提供灵活收费模式 |
| Amazon Neptune | 专为图数据库设计的交互式开发环境,基于 Jupyter Notebook | 需要处理图数据库和知识图谱的应用,特别是大规模图数据的查询和分析 | Amazon Neptune 图数据库资源,支持复杂图数据操作 | 与 AWS 其他服务如 S3、Lambda 集成,适合云端图数据库应用 | 基于 Jupyter Notebook 界面,友好,适合数据分析和开发 | 支持与 AWS 其他服务集成,扩展性较强 | 按计算资源和服务收费,适合企业级图数据库应用 |
| TigerGraph Notebooks | 专为图数据库开发和分析设计的交互式环境,集成 TigerGraph 图数据库引擎 | 适合大规模图数据处理和分析,特别是知识图谱和社交网络分析等应用 | TigerGraph 图数据库资源,支持复杂图计算 | 与 TigerGraph 数据库深度集成,支持复杂的图查询和分析 | 基于 Jupyter Notebook 界面,专业,适合图数据科学工作流 | 支持与 Python 数据科学工具集成,扩展性强 | 按计算资源和服务收费,提供企业级支持 |
2.1 Google Colab
- 基本功能:提供免费的在线 Jupyter Notebook 环境,支持 Python 和其他常用数据科学库,内置代码片段库、可视化插件、Markdown 支持以及版本控制功能。
- 使用场景:主要用于数据科学和机器学习,适合初学者和轻量级项目。
- 后台使用的计算资源:可以连接到 Google Cloud 的计算资源,支持 GPU 和 TPU 加速。
- 与自家生态结合程度:与 Google 的各类产品,如 Google Drive、Google Cloud 等紧密集成。
- 用户界面:简单易用,类似 Jupyter Notebook,界面清爽。
- 扩展性:支持连接到本地 Jupyter Notebook 和 Google Cloud,扩展性较强。
- 商业化方式:提供免费的基本服务,高级版本提供更多计算资源和更长的运行时间。
- https://colab.research.google.com/
2.2 AWS SageMaker
- 基本功能:专注于机器学习的开发平台,集成 Jupyter Lab、RStudio、Canvas 等应用,支持端到端的机器学习生命周期管理。
- 使用场景:适合需要进行大规模机器学习模型训练、部署和管理的企业级用户。
- 后台使用的计算资源:依托 AWS 的云计算资源,支持大规模分布式训练,特别是定制化的 PyTorch 环境。
- 与自家生态结合程度:与 AWS 的服务深度集成,如 S3、Lambda、CloudWatch 等。
- 用户界面:提供托管的 Jupyter Notebook 界面,界面简洁,功能强大。
- 扩展性:支持 MLOps 工作流的自动化和扩展,能够轻松集成 AWS 的其他服务。
- 商业化方式:按需收费,基于使用的计算资源和存储收费。
- https://aws.amazon.com/cn/sagemaker/
- https://docs.aws.amazon.com/sagemaker/
- https://aws.amazon.com/cn/sagemaker/getting-started/?refid=ap_card
2.3 Databricks Notebook
- 基本功能:基于 Apache Spark 的数据分析平台,支持多语言编程、数据处理和机器学习开发。
- 使用场景:适合大数据处理、数据工程和机器学习任务,特别是在 Spark 环境中。
- 后台使用的计算资源:使用云端的 Spark 集群进行计算,支持大规模并行计算。
- 与自家生态结合程度:原生与 Apache Spark 集成,Databricks 与 Azure 的版本(Azure Databricks)与 Azure 服务集成更紧密。
- 用户界面:类似 Jupyter Notebook,支持多语言,提供协作和版本控制功能。
- 扩展性:高度可扩展,支持与多种云服务和 BI 工具集成。
- 商业化方式:按使用的计算资源收费,提供企业级功能和支持。
- https://learn.microsoft.com/zh-cn/azure/databricks/notebooks/
- https://help.aliyun.com/document_detail/168130.html
- https://docs.databricks.com/en/index.html
- https://learn.microsoft.com/zh-cn/azure/databricks/scenarios/databricks-extract-load-sql-data-warehouse
2.4 火山引擎
- 基本功能:提供在线 Jupyter Notebook 环境,主要支持 Python 和 Python Spark 内核。
- 使用场景:适合需要使用 Spark 进行大数据处理的用户,主要用于数据分析和机器学习任务。
- 后台使用的计算资源:使用 Spark 集群进行计算。
- 与自家生态结合程度:与火山引擎的其他服务集成,提供高效的数据处理能力。
- 用户界面:基于 Jupyter Notebook 的界面,简单易用。
- 扩展性:支持 Python 和 Spark,扩展性中等。
- 商业化方式:基于使用的计算资源按时长收费。
- https://www.volcengine.com/docs/6260/106517
2.5 Azure Machine Learning Notebooks
- 基本功能:为构建、训练和部署机器学习模型提供全托管的 Jupyter Notebook 环境。
- 使用场景:适合企业级用户进行端到端的机器学习开发和部署。
- 后台使用的计算资源:使用 Azure 云资源进行计算,支持大规模分布式训练。
- 与自家生态结合程度:深度集成 Azure 服务,如 Azure 数据存储、Azure DevOps 等。
- 用户界面:基于 Jupyter Notebook,集成了 Azure Machine Learning 的特性,界面统一。
- 扩展性:支持与 Azure 的各类服务和工具集成,扩展性极强。
- 商业化方式:按使用的计算资源和服务收费。
- https://learn.microsoft.com/zh-cn/azure/machine-learning/how-to-run-jupyter-notebooks?view=azureml-api-2
2.6 Kaggle Notebook
- 基本功能:提供完全托管的 Jupyter Notebook 环境,预装常用的数据科学和机器学习库,并直接访问 Kaggle 的公开数据集。
- 使用场景:适合数据科学家、分析师和机器学习工程师进行竞赛、探索和学习。
- 后台使用的计算资源:提供免费的 CPU、GPU 和 TPU 资源。
- 与自家生态结合程度:深度集成 Kaggle 平台,支持访问 Kaggle 数据集和竞赛。
- 用户界面:基于 Jupyter Notebook,界面简单,易于使用。
- 扩展性:支持与 Kaggle 的竞赛和数据集集成,扩展性较为有限。
- 商业化方式:免费提供,适合初学者和竞赛参与者。
- https://www.kaggle.com/docs/notebooks
2.7 IBM Watson Studio Notebook
- 基本功能:基于云的交互式开发环境,支持多种编程语言和机器学习开发,深度集成 IBM 数据和 AI 服务。
- 使用场景:适合企业级数据科学、机器学习和人工智能开发与部署。
- 后台使用的计算资源:提供强大的云端计算资源,支持大规模数据处理和模型训练。
- 与自家生态结合程度:与 IBM 的数据与 AI 服务深度集成。
- 用户界面:基于 Jupyter Notebook,界面简洁,功能强大。
- 扩展性:支持与 IBM 云服务的深度集成和扩展,适合复杂的企业级工作流。
- 商业化方式:按使用的计算资源和服务收费。
- https://www.ibm.com/docs/en/cloud-paks/cp-data/5.0.x?topic=models-notebooks-scripts
2.8 Paperspace Gradient Notebook
- 基本功能:云端 Jupyter Notebook 环境,专门用于机器学习和深度学习的开发,提供 GPU 和 TPU 计算资源。
- 使用场景:适合需要强大计算资源进行深度学习和机器学习模型开发的用户。
- 后台使用的计算资源:提供 GPU 和 TPU 加速,支持大规模计算任务。
- 与自家生态结合程度:与 Paperspace 的 Gradient 平台集成,支持从开发到部署的全流程自动化。
- 用户界面:基于 Jupyter Notebook,功能丰富,易于使用。
- 扩展性:支持与 Gradient 平台的集成,扩展性较强。
- 商业化方式:按使用的计算资源收费,适合企业级用户。
- https://www.paperspace.com/notebooks
2.9 Google AI Platform Notebook
- 基本功能:Google Cloud 提供的托管 Jupyter Lab 服务,支持数据科学、机器学习和深度学习开发。
- 使用场景:适合需要使用 Google Cloud 资源进行机器学习和数据科学任务的用户。
- 后台使用的计算资源:使用 Google Cloud 的计算资源,支持 GPU 和 TPU 加速。
- 与自家生态结合程度:深度集成 Google Cloud 服务,如 BigQuery、Cloud Storage 等。
- 用户界面:基于 Jupyter Lab,界面现代化,功能全面。
- 扩展性:支持与 Google Cloud 的广泛服务集成,扩展性极强。
- 商业化方式:按使用的计算资源和服务收费。
- https://medium.com/google-cloud/how-to-use-google-ai-platform-notebooks-for-your-data-science-team-26d9eefc8ce0
2.10 Domino Data Lab Notebook
- 基本功能:企业级的数据科学平台,提供基于 Jupyter Notebook、RStudio 和 Zeppelin 的云端开发环境。
- 使用场景:适合企业级数据科学、数据工程和机器学习任务,支持大规模数据处理和自动化工作流。
- 后台使用的计算资源:支持配置和管理计算资源,如 CPU、GPU,按需扩展。
- 与自家生态结合程度:与企业的内部系统和工具集成,支持复杂的企业级工作流。
- 用户界面:多工具支持,界面专业,适合企业用户。
- 扩展性:高度可扩展,支持多种编程语言和工具,适合复杂的企业应用。
- 商业化方式:按使用的计算资源和服务收费,提供企业级功能和支持。
- https://domino.ai/solutions/jupyter
2.11 CoCalc
- 基本功能:在线协作平台,支持 Jupyter、Julia、LaTeX 等多种计算工具,专为科学计算、数据科学和教育设计。
- 使用场景:适合教育、研究和团队协作,支持复杂的科学计算和数据分析任务。
- 后台使用的计算资源:用户可以选择计算资源,按时长收费,适合不同规模的计算需求。
- 与自家生态结合程度:独立的平台,支持多种工具的协同使用。
- 用户界面:多工具支持,界面灵活,适合教育和研究使用。
- 扩展性:支持多种编程语言和工具,扩展性较强。
- 商业化方式:按计算资源和使用时长收费,提供灵活的收费模式。
- https://doc.cocalc.com/
2.12 Amazon Neptune Notebook
- 基本功能:专为图数据库和知识图谱设计的交互式开发环境,基于 Jupyter Notebook,深度集成 Amazon Neptune 图数据库。
- 使用场景:适合需要处理图数据库和知识图谱的应用,特别是大规模图数据的查询和分析。
- 后台使用的计算资源:使用 Amazon Neptune 图数据库的资源,支持复杂的图数据操作。
- 与自家生态结合程度:与 AWS 的其他服务(如 S3、Lambda)集成,适合云端图数据库应用。
- 用户界面:基于 Jupyter Notebook,界面友好,适合数据分析和开发。
- 扩展性:支持与 AWS 的其他服务集成,扩展性较强。
- 商业化方式:按使用的计算资源和服务收费,特别适合企业级图数据库应用。
- https://docs.aws.amazon.com/neptune/latest/userguide/graph-notebooks.html
2.13 TigerGraph Notebooks
- 基本功能:专为图数据库开发和分析设计的交互式环境,基于 Jupyter Notebook,集成 TigerGraph 的图数据库引擎。
- 使用场景:适合需要进行大规模图数据处理和分析的企业用户,特别是知识图谱和社交网络分析等应用。
- 后台使用的计算资源:使用 TigerGraph 的图数据库资源,支持复杂图计算。
- 与自家生态结合程度:深度集成 TigerGraph 数据库,支持复杂的图查询和分析。
- 用户界面:基于 Jupyter Notebook,界面专业,适合图数据科学工作流。
- 扩展性:支持与 Python 数据科学工具的集成,扩展性强。
- 商业化方式:按使用的计算资源和服务收费,提供企业级支持。
- https://docs.tigergraph.com/ml-workbench/current/on-cloud/notebooks
3. 架构原理
下面对目前能够找到相关资料的 Notebook 商业化服务的架构原理进行总结梳理。
3.1 AWS SageMaker
下图描述了 AWS SageMaker Studio Classic notebook 的架构原理:
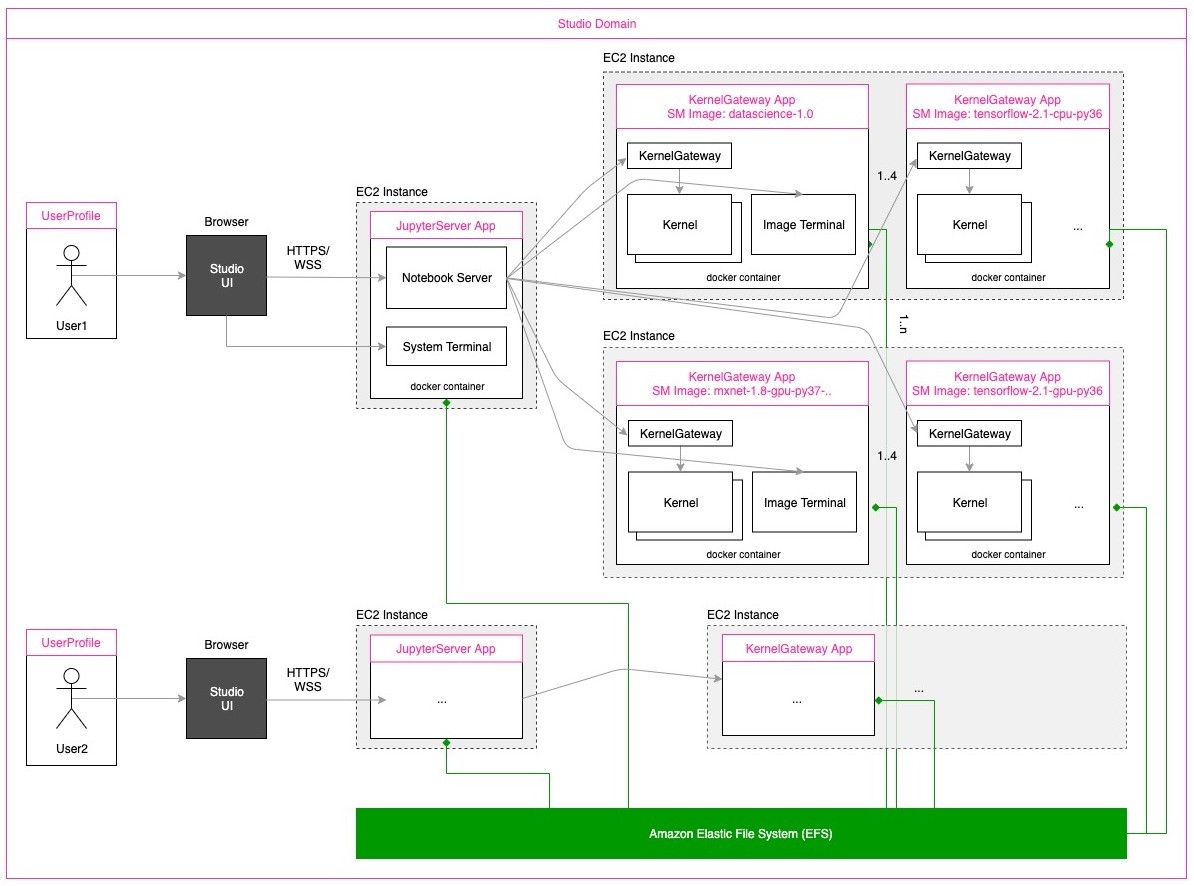
在架构方面,用户通过 Studio 可以访问 Jupyter 的前端。每个用户都有一个独立的 EC2 实例,将Jupyter Server 部署在这个 EC2 实例的容器里面。Kernel 可以部署在不同算力的 EC2 实例内的容器里面,并通过 Kernel Gateway 与 Jupyter Server 进行通信。并且 Kernel 所在的容器可以基于用户自定义的镜像进行构建。
在存储方面,Jupyter Server 和 Kernel Gateway 都会连接到共享的 Amazon EFS。EFS 提供持久存储,因此即使单个 EC2 实例被停止或重启,用户数据也会被保留。
这种架构的优点是更具有扩展性和能够进行更灵活的资源分配,缺点是占用的计算资源会比较多、比较难管理。
参考资料:
Dive deep into Amazon SageMaker Studio Classis Notebooks architecture
3.2 Databricks Notebook
下图描述了 Databricks 的架构:

Databricks 的 Notebook 属于 控制平面(Control Plane)的一部分。通过它,用户可以编写代码、执行数据处理任务、以及与后端的计算资源交互。后端的计算资源可以位于云端,例如 AWS Spark 集群等。后端的计算资源可以读写存储在本地或云端的数据资源。
Databricks Notebook 更详细的架构原理资料暂时还没有找到。
参考资料:
Databricks architecture overview
3.3 火山引擎
下面的图片是火山引擎 DataLeap notebook 的基础结构原理图:
在架构方面,DataLeap 中 notebook 的前端使用的是经过二次开发的 Jupyter Lab。为节省资源,为每个项目启动一个 Jupyter Server,而不是为每个用户启动一个 Jupyter Server。Jupyter Server 通过 Enterprise Gateway 来连接部署在集群中的 Kernel。
在存储方面,把 Notebook 代码文件存放在 OSS 上,这样可以实现代码的共享。把管理用户到 Kernel 的 Session 信息存储在 Mysql 中,提高连接的可靠性。
这种架构适合 to c 的场景,具备更高的性能,但是维护难度更大。
参考资料:
3.4 Amazon Neptune Notebook
下面图片是 Amazon Neptune Notebook 的架构原理图:
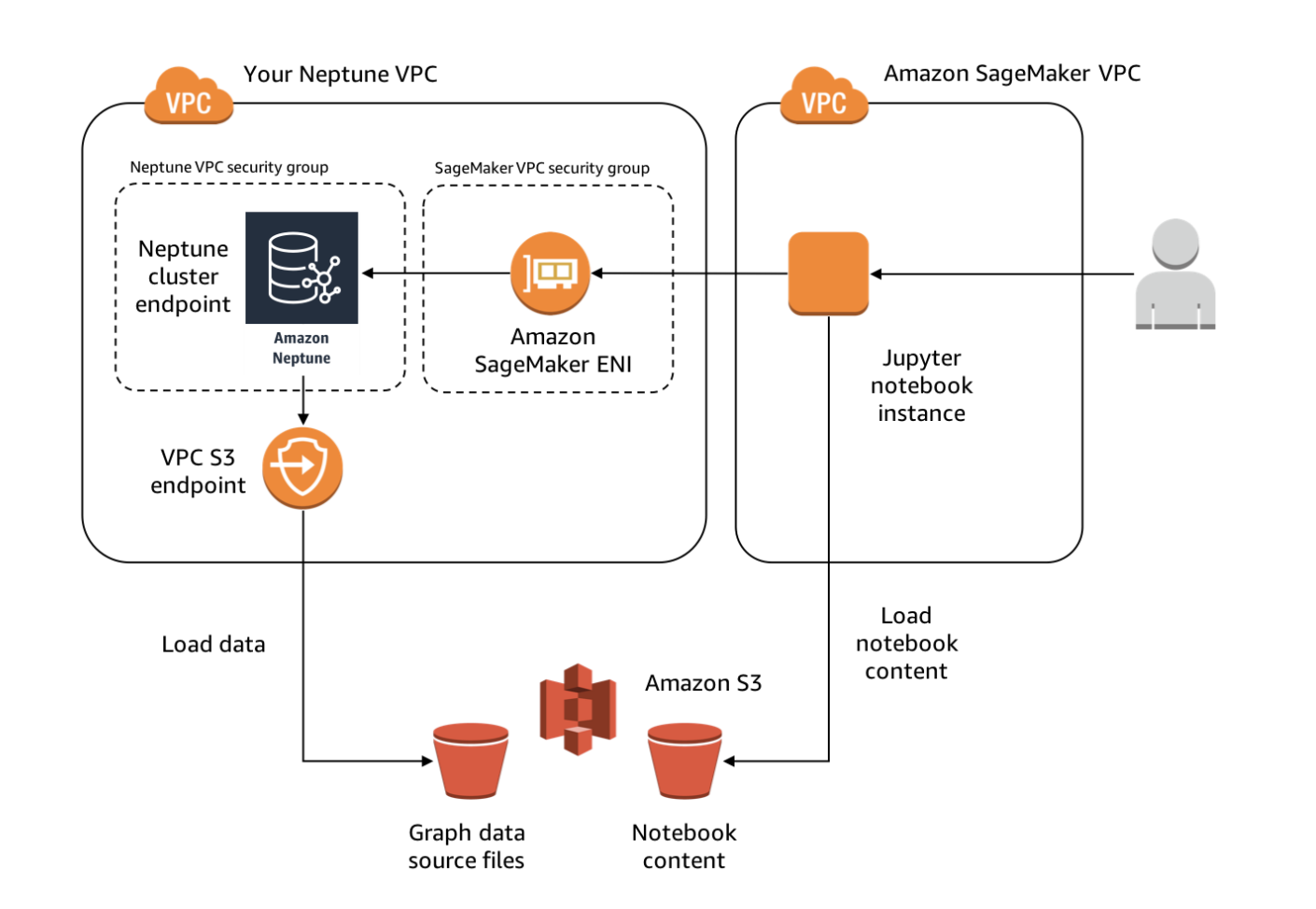
用户在 Jupyter Notebook 实例中运行代码时,Notebook 会通过 SageMaker ENI 与 Neptune 集群通信,执行图查询并获取结果。Notebook 的内容可以存储在 S3 中,这样用户可以方便地加载和保存他们的工作内容,并在不同的 Notebook 实例之间共享这些内容。Amazon Neptune 图数据库通过 VPC S3 端点从 Amazon S3 加载图数据源文件到图数据库中。用户可以将这些数据用于图分析和模型训练,并通过 Jupyter Notebook 进行访问。
参考资料:
Explore use cases using Neptune
3.5 美团内部数据系统 Notebook
下图是美团内部数据系统 notebook 的架构原理图:
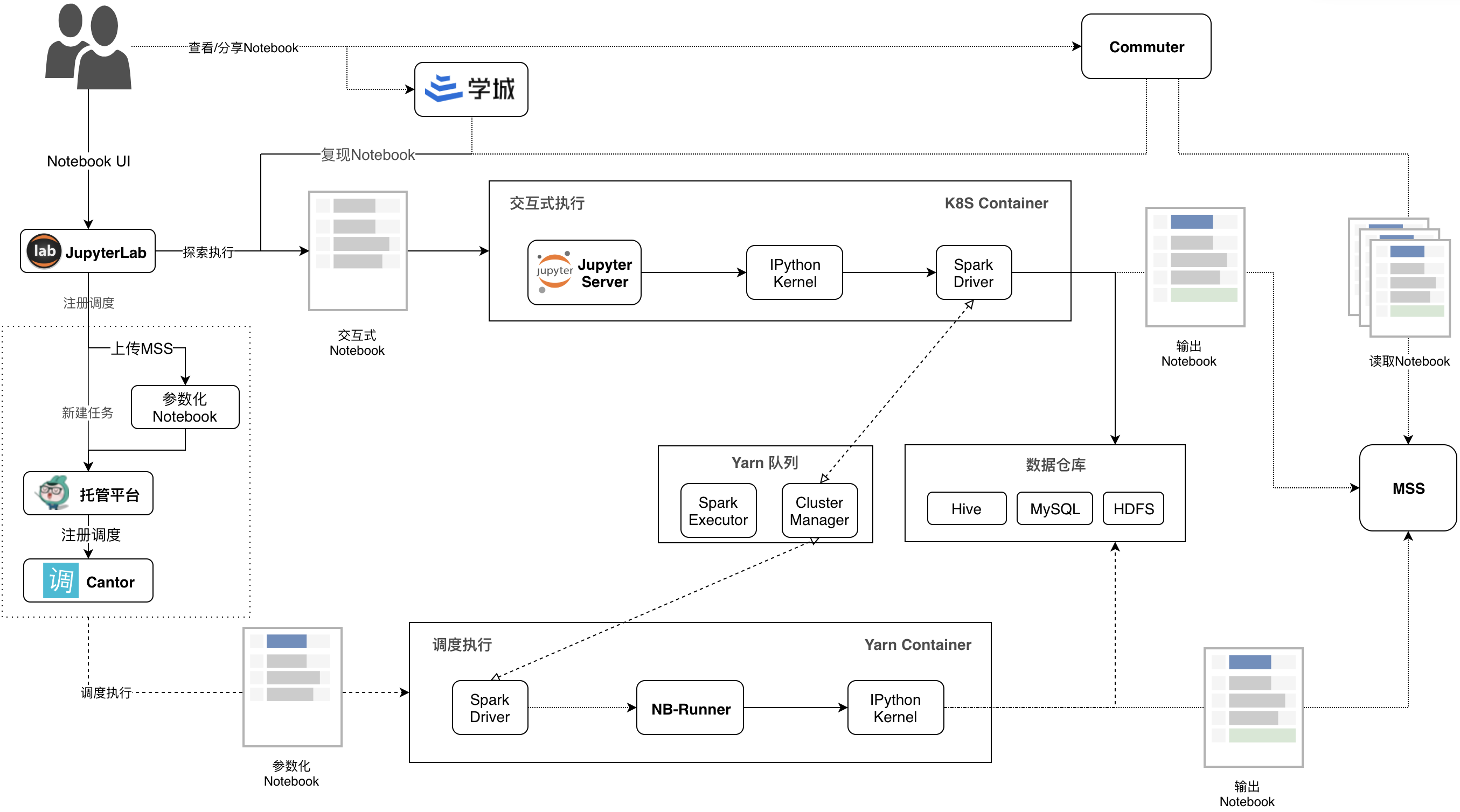
在架构方面,通过 Jupyter Hub 来部署 Jupyter Server 和 Kernel 实例。基于 Jupyter Hub 接入数据系统的验证方式。Jupyter Server 和 Kernel 实例 部署在 K8s 的容器里面,会为每个用户创建一个实例容器。用户可以通过 pyspark 来操作 spark 集群。用户编写的 ipynb 代码文件,基于 nbconvert 可以在调度系统里面执行。
在部署方面,代码文件会上传到对象存储,实现文件的共享。
这种架构适合 to b 场景,维护起来比较简单。
参考资料:
4. 图数据库相关
上面介绍的 Notebook 商业化产品中,Amazon Neptune Notebook 和 TigerGraph Notebooks 都通过 Jupyter Notebook 提供了交互式的开发环境,用户可以在这个环境中编写代码、运行查询、并可视化结果。这些 Notebooks 直接集成了各自的图数据库(Amazon Neptune 和 TigerGraph),使用户能够在 Notebook 中直接与图数据库进行交互。
在集成深度方面:这两款 Notebook 都深度集成了各自的图数据库引擎。Amazon Neptune Notebook 与 AWS 生态系统有紧密的结合,能够直接调用如 S3 存储、Lambda 函数等服务。而 TigerGraph Notebooks 则侧重于集成 TigerGraph 的图数据库功能,支持复杂的图查询和分析。
在计算资源方面:Amazon Neptune Notebook 依赖于 Amazon Neptune 图数据库的计算资源,特别是在处理大规模图数据时,能够利用 Neptune 提供的高效查询和存储功能。TigerGraph Notebooks 则利用 TigerGraph 图数据库的资源,支持复杂图计算和图分析。
在 Jupyter Notebook 中访问图数据库主要有两种方法。首先,可以使用 Python 第三方库(如 neo4j-python-driver)直接连接图数据库,并通过安装可视化插件将数据可视化,这种方式灵活且适合已有 Python 技术栈的用户。其次,Apache Zeppelin 提供了 Neo4j Interpreter,用户可以通过 magic 命令直接操作图数据库,这种方法集成度高,适合需要快速上手和以图数据库查询为主的工作流。
总而言之,Notebook 连接图数据库资源,其实就是访问图数据库对外暴露的访问接口。
5. Spark 相关
在 Notebook 中访问和操作 Apache Spark 通常通过像 Databricks Notebook 这样的平台进行。这些平台提供了强大的数据分析和处理能力,特别适合大规模数据处理、数据工程和机器学习任务。Databricks Notebook 基于 Apache Spark 构建,支持多语言编程,并利用云端的 Spark 集群进行并行计算,借助 Spark 的分布式计算框架高效处理和分析海量数据。
Databricks Notebook 与 Spark 的深度集成使得用户能够直接在 Notebook 环境中运行 Spark 作业,无需额外配置。用户可以通过 Notebook 编写多种编程语言的代码(如 Python、SQL、Scala 等),直接操作 Spark 数据集并实时查看计算结果。此外,Databricks 支持与 Azure 等云服务的紧密集成,特别是在 Azure Databricks 中,用户可以无缝访问 Azure 的数据存储、计算和机器学习服务,实现端到端的数据处理和分析。平台的高度扩展性还允许与多种 BI 工具和云服务集成,满足企业多样化的需求。商业化方面,Databricks 按计算资源收费,提供企业级功能和支持,非常适合需要处理大规模数据的企业使用。
总而言之,Notebook 连接 Spark 资源,其实就是连接到 Spark 资源对外暴露的访问接口。在 Jupyter Notebook 中,可以通过 PySpark、Apache Livy、Databricks Connect 或 Hadoop YARN 等工具和配置,将 Notebook 连接到本地或远程的 Spark 集群资源,从而直接在 Notebook 中执行 Spark 作业,实现大规模数据处理和分析。也可以通过扩展相关的 magic 命令,来编写 Spark 的代码。
6. 总结
目前主流的 Notebook 商业化服务大多基于 Jupyter 进行二次开发,但各厂商的开发程度不同。例如,Google Colab 对 Jupyter 进行了较深的二次开发,创建了自己的前端,并将 Jupyter 的后端部署在其自有的计算资源上,实现商业化。而 AWS SageMaker 则对 Jupyter 进行的二次开发较少,主要是将其集成到平台上,并对接平台的资源。
通过分析主流的 Notebook 商业化服务,可以看出,不同任务需要不同类型的 Notebook。在 Notebook 的后端,如果只需要纯 Python 环境,只需将 Jupyter 后端安装在相应的计算资源上即可。而如果需要连接 Spark、图数据库等资源,则需提前配置好这些资源,并在用户启动实例时自动连接。在使用方面,可以开发相应的 magic 命令,以便用户在每个单元格执行前指定语言,或统一配置实例使用的编程语言。